Faster Python with Go shared objects (the easy way)


There's no two ways about it, Python is slow.
I felt this in particular when exploring how to sanitize potentially malicious HTML content in the CTFd content editor.
The two options for sanitizing/processing HTML in Python both have some tradeoffs:
- Poorly but quickly parse HTML with the available HTML4 parsers (e.g.
html.parser,lxml's default options) - Slowly but correctly parse HTML5 with
html5lib(pretty much all Python HTML5 parsers rely onhtml5lib)
I began trying lots of the traditional techniques to see if I could speed up the HTML processing.
For example:
- Using more efficient Python language constructs and trying to rewrite code to not be slow 🧠
- Adding threading or multiprocessing (and dealing with whatever problems that causes)
- Compiling your Python code using Cython
- Giving up and using PyPy
Nothing I tried really made a meaningful difference.
I knew that another way to speed up Python was to rewrite everything in another language rewrite slow code in another language and call that code from Python.
But maybe I can guess what you're thinking:
If I'm trying to write faster Python it's because I didn't really want to write C in the first place.
And you would be right! Do you really want to write that C code? Or the ctypes code for that matter?
But let's talk about how we can solves this while writing as little C as possible.
Go Shared Objects
Google's Go programming language has the ability to generate shared libraries/objects which can be loaded by other applications. Those applications can then access the compiled Go code without having to have a Go compiler or know anything about Go.
And if you didn't already know, Python has the ability to import code from shared objects! It's this functionality that many libraries leverage to make certain parts of "Python" code go faster. The difference from the norm here is that we're going to use Go to generate the shared object.
This strategy comes with some benefits and drawbacks that should be stated up front. Most other posts discussing this topic were not clear about the drawbacks and I think some of them are why we're not seeing more Python modules written in Go despite it being a very capable choice.
Pros:
- Golang is much easier to write than C
- Complex tasks (like HTML parsing) have much less risk of memory corruption in Go than in C
- Go's standard library and ecosystem is expansive and easy to access
- A lot of code will be generated for you so you're only ever really writing Python and Go
Cons:
- Unfortunately we still need to manage memory a little
- It's hard to pass non-primitive types between Golang and Python. Or at least I haven't properly worked it out.
- Python packaging is already kind of hard and adding Go into the mix makes it harder. Go's cross-compiliation tools aren't that helpful either but they might be in the future.
Obviously you should only use this technique in specific situations. I'm summarizing something that's worked well for me but you should evaluate and benchmark whether it makes sense.
With that out of the way, onto the code!
Writing our faster code
I'm going to ignore talking about it, but you should get a working Go environment setup. If you can run a Go hello world example, you're good to go. Unfortunately this post won't be a good resource for learning Go but there's far better places for that.
Let's start with a basic example.
package main
import "C"
import "fmt"
//export hello
func hello() {
fmt.Println("Hello World!")
}
func main() {}
This code obviously just prints "Hello World!" when you call the hello() function. However the magic is in two lines:
import "C"//export hello
Importing C enables Go to call C code but also tells the compiler to generate header files that let Go code be called from C. Relevant Go documentation
The export line instructs the Go compiler to export the function beneath the comment to the generated header file so it can be called by other applications. Relevant Go documentation
Next we will compile this code. Run the following command in the same directory as the above hello.go file.
go build -buildmode=c-shared -o hello.so .This instructs the compiler to build a shared object and relevant header file.
-buildmode=c-shared
Build the listed main package, plus all packages it imports,
into a C shared library. The only callable symbols will
be those functions exported using a cgo //export comment.
Requires exactly one main package to be listed.Afterwards you should now also have hello.h and hello.so:
❯ ls -1
hello.go
hello.h
hello.soWe won't use the header file just yet but don't delete it. We will need to copy the functions marked extern from it in the next section. In this case we would care about the extern int hello(); line near the bottom.
Now you can technically use ctypes to interface with the shared object that was generated.
❯ ipython
Python 3.8.5 (default, Jul 21 2020, 10:48:26)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.19.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import ctypes
In [2]: hello = ctypes.CDLL("hello.so")
In [3]: hello.hello()
Hello World!
Out[3]: 0This is cool but it will become harder as we make more complicated functions.
More complicated functions
Okay let's expand our original example to make it more complicated.
Let's accept and return a string.
package main
import "C"
//export hello
func hello(name *C.char) *C.char {
goName := C.GoString(name)
result := "Hello " + goName
return C.CString(result)
}
func main() {}This starts to complicate our original example, and starts to reveal the difficulties of writing Go shared modules.
It also introduces a memory leak!
So what's going on here?
-
If we want to pass data in or out, we need to use the C types provided by Go. These aren't well documented by Go but there are some online references.
In our example, our function needs to accept and return*C.char. -
Then to use those C types as a Go variable we need to convert it back into a Go string with
C.GoString -
Finally to return it back out as a
*C.charwe need to useC.CString()to convert the Go string back. -
However
C.CStringcreates a string usingmalloc()and thus needs to be freed (which we haven't). Go will not warn you about this mistake. Only you can preventforest firesmemory leaks. Here's a snippet from the Go docs:// The C string is allocated in the C heap using malloc. // It is the caller's responsibility to arrange for it to be // freed, such as by calling C.free (be sure to include stdlib.h // if C.free is needed).
Let's ignore the memory leak for now. We will address it later.
Once again we can call this example with ctypes but it also gets a little more complicated. Now that we have parameters and return values we need to provide the types for both from Python.
import ctypes
hello = ctypes.CDLL("hello.so")
# Specify a list of all of the types for the arguments
hello.hello.argtypes = [ctypes.c_char_p]
# Specify the type of the return value
hello.hello.restype = ctypes.c_char_p
# Encode our string into bytes
name = "Dude".encode("utf-8")
# Call the function and store the returned value
response = hello.hello(name)
print(response) # b'Hello Dude'This isn't too bad but it's quite annoying to rewrite our type declarations using the ctypes API. Especially as the amount of functions we add grows. There's also the chance that you'll get the type declarations wrong. I have no idea what happens in that scenario.
But there's a better way!
CFFI
The CFFI library allows us to interface with the shared object more easily by letting us directly copy the type specification from Go's generated header files. It also has functions that let us more easily convert a returned pointer into the appropriate Python data structure.
So let's follow CFFI's "Main mode of usage" to build a secondary shared object that will wrap our existing shared object with CFFI's glue code.
Create a new script named build_ffi.py:
from cffi import FFI
ffibuilder = FFI()
# Specify the header that was generated by the Go compiler for source
# Specify the shared object that was generated by the Go compiler for extra_objects
ffibuilder.set_source(
module_name="hello",
source="""
#include "hello.h"
""",
extra_objects=["hello.so"],
)
# Copy the extern functions at the bottom of the header file (e.g. hello.h)
ffibuilder.cdef(
csource="""
extern char* hello(char* p0);
"""
)
if __name__ == "__main__":
ffibuilder.compile(verbose=True)We want to provide cffi with the necessary details to be able to build a wrapper shared module so we will need to provide:
- Our generated header file
- Our generated shared object file
- The list of shared object functions that we wish to be able to call. This was already generated for you by the Go compiler near the bottom the
hello.hfile. You can just copy & paste it tobuild_ffi.py. Perhaps you could automatically extract it but that's for a later project.
Once the script is created, run it and you should get something like this:
❯ python build_ffi.py
generating ./hello.c
(already up-to-date)
running build_ext
building 'hello' extension
clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers -I/usr/local/Cellar/python@3.8/3.8.5/Frameworks/Python.framework/Versions/3.8/include/python3.8 -c hello.c -o ./hello.o
clang -bundle -undefined dynamic_lookup -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk ./hello.o hello.so -o ./hello.cpython-38-darwin.soYou will also see a few new files:
hello.chello.cpython-38-darwin.so(or some other shared object equivalent)hello.o
We care about the new hello.cpython-38-darwin.so file. Again the name may be different depending on your OS.
With CFFI the code to interact with the shared object is a little different:
from hello import lib, ffi
name = b"Guy"
r = lib.hello(name)
print(r) # <cdata 'char *' 0x7ff309706230>
print(ffi.string(r)) # b'Hello Guy'Essentially our exported functions are available on the lib module and the ffi module provides functions to convert & create between C & Python types.
The full process of interacting with the generated shared object is specified in the CFFI documentation.
Now you can take the generated shared object and write simple Python wrapper code. Users won't ever have to know the dark secret that the actual code isn't even in Python.
The Pitfalls
Most of the existing discussion around this topic simply stops here. It's all perfect, their Hello World Golang module is happily running in production with nary a blip in sight.
That was not the case for me as I ran into a few issues with Go FFI:
- Memory leaks are easy to introduce but it's unclear how to avoid it
- It's hard to pass non-primitive types between Go and Python
It's entirely possible I came up with something suboptimal. If you have better solutions I'd love to hear from you!
Memory Leaks
Let's follow up on our previous example:
package main
import "C"
//export hello
func hello(name *C.char) *C.char {
goName := C.GoString(name)
result := "Hello " + goName
return C.CString(result)
}
func main() {}I mentioned that this code had a memory leak due to the usage of C.CString() without a subsequent free(). How do you solve this?
The cgo documentation says you should call C.free():
package main
// #include <stdlib.h>
import "C"
import "unsafe"
func main() {
cs := C.CString("Hello from stdio")
C.free(unsafe.Pointer(cs))
}Okay but if I do that how do I return the data to my module? Is there a way to free after I return?
If you dig a little deeper, you will find the defer statement which will defer the execution of a function until the surrounding function returns.
package main
// #include <stdlib.h>
import "C"
import "unsafe"
func main() {
cs := C.CString("Hello from stdio")
// Wait for the function to return before freeing
defer C.free(unsafe.Pointer(cs))
}The issue with this strategy, if implemented, is that Python will be holding onto a dangling pointer. The pointer will be pointing to a memory location that has been freed so it might change at any point. Here be dragons as they say.
Instead what I settled on was to export a C.free() wrapper function that I could call from Python after I had copied the data. So for example:
package main
// #include <stdlib.h>
import "C"
import "unsafe"
//export hello
func hello(name *C.char) *C.char {
goName := C.GoString(name)
result := "Hello " + goName
return C.CString(result)
}
//export FreeCString
func FreeCString(s *C.char) {
C.free(unsafe.Pointer(s))
}
func main() {}Which we then access from Python as:
from hello import lib, ffi
name = b"Guy"
# Store a pointer to the return value
r = lib.hello(name)
# Copy out the string value
value = ffi.string(r)
# Free the pointer
lib.FreeCString(r)
# Value is still available
print(value)
# You can also verify that:
# - the id() is different
# - cffi uses the proper Python C API functions to copy the value
# https://foss.heptapod.net/pypy/cffi/-/blob/branch/default/cffi/api.py#L302-318
# https://foss.heptapod.net/pypy/cffi/-/blob/branch/default/c/_cffi_backend.c#L6749-6859
# https://docs.python.org/3/c-api/bytes.html#c.PyBytes_FromStringAndSizePassing data between Go and Python
As I mentioned earlier, it's difficult to pass non-primitive data between Python. You're kind of limited to things like short, int, long, char, float, double and things based off of them.
Say you created a nice Go struct (basically a class) that had all the fields and methods what you wanted. If you're a beginner like me, you might think that you can magically pass that struct over to Python somehow and use it like a regular Python class or something.
That's not the case.
I found that the simplest strategy was to keep Go objects within the Go side and Python objects within the Python side and pass primitive references to each other.
So for example:
package main
/*
#include <stdlib.h>
*/
import "C"
import (
"math/rand"
"github.com/microcosm-cc/bluemonday"
)
var POLICIES = map[uint32]*bluemonday.Policy{}
func GetPolicyId() uint32 {
policyId := rand.Uint32()
for {
if POLICIES[policyId] == nil {
break
} else {
policyId = rand.Uint32()
}
}
return policyId
}
//export NewPolicy
func NewPolicy() C.ulong {
policyId := GetPolicyId()
policy := bluemonday.NewPolicy()
POLICIES[policyId] = policy
return C.ulong(policyId)
}
func main() {}And the relevant Python code:
from bluemonday import lib, ffi
class NewPolicy(Policy):
def __init__(self):
self._id = lib.NewPolicy()
p = NewPolicy()The strategy here is that I generate a "random" ID using GetPolicyId() and NewPolicy() and pass it to the Python code. Similarly, when I would want to call a method on the Go struct, I pass the identifier back to the Go code to identify which instance of the struct I would like to use, and use reflection to call the appropriate method based on a string I provide.
These two strategies are not necessarily the best and there may be issues that I haven't encountered yet. For example, the Python side could cause some issues by corrupting the _id attribute or by forgetting to free memory, but I haven't come up with a better solution yet.
If you know better than me please reach out!
The End Result
Originally I hoped to build something on top of lxml's Cleaner module by getting a faster language (maybe Rust) to do the processing and then have lxml do the cleaning. This was honestly never going to work in a reasonable amount of time.
But there was a major breakthrough when a friend showed me the bluemonday library.
bluemonday implements a whitelist based HTML sanitizer built on top of x/net/html, Golang's "HTML5-compliant tokenizer and parser". bluemonday provided a lot of knobs that could be tweaked for very flexible sanitization and was being used on a lot of projects that contained user contributed content.
But no Python bindings... until now!
pybluemonday implements Python bindings to bluemonday using the same techniques I outlined in this post. You can think of it as the advanced summary of everything discussed here.
I built a small benchmarking script to compare the speed of pybluemonday to the standard Python HTML sanitizer libraries and the results were very impressive:
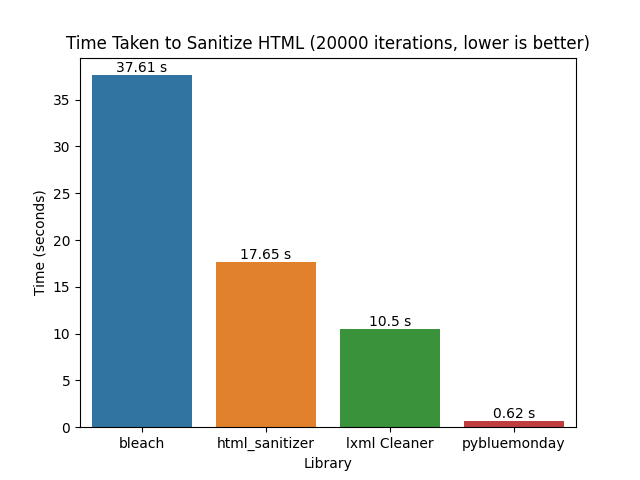
As you can see by keeping all of the processing and sanitization logic within Go, we benefit from significant speed gains. Essentially we only pass data back into Python when it's ready to use.
This post tackles a lot of the initial difficulties I ran into while writing Python modules in Go. It's not as ergonomic as writing everything in Python but I feel it likely provides an equivalent amount of speed as writing directly in C with much less of the difficulty of writing raw C code.
There may be some memory overhead because the Go runtime is probably statically compiled into the shared object but I think it's a worthwhile trade off.
Additionally I didn't write about the packaging aspect of this but pybluemonday has wheels for all the major targets (Linux, OSX, Windows). This is based off of cibuildwheel and setuptools-golang. Perhaps I will cover how to do this in a future post as it was not trivial to setup.
I hope this post clears up some of the confusion around using Go for Python modules and I hope the process gets easier over time.